
Introduction
In this article, we will evaluate two RAG platforms, Nuclia and Vectara, leveraging the open source REMi evaluation model and the nuclia-eval library (learn more about the REMi model here). Our goal is to compare the performance of the two platforms and to explore the results of different configurations and how they are reflected in the metrics.
By using a standardized evaluation framework like REMi, we ensure that the comparison is both fair and rigorous, offering valuable insights into the capabilities of these leading RAG solutions.
Dataset
Publicly available datasets for evaluating RAG are scarce. However, general document-question-answer datasets can be adapted for this purpose by adding the documents to the knowledge base and using the questions as queries.
For this evaluation, the Docmatix dataset was used. Created by the Hugging Face team for fine-tuning their vision-language model Idefics3, this dataset was initially an image-question-answer dataset. Upon request, they uploaded the documents in PDF format. This dataset is massive, with over 1.4 million documents and multiple question-answer pairs for each document.
To have a more manageable dataset size, it was reduced to a subset containing the first 0.1% of the documents and the first question-answer pair for each document, totaling 1.405 documents and 1.405 question-answer pairs. We refer to this subset as “Docmatix 1.4k”.
It is important to note that since this dataset is not specifically designed for RAG evaluation, it contains questions such as “What is the title of the document?” or “Who is the author of the text?”. These questions are generic and lack useful retrieval information, as they are meant to be answered directly from the document without a retrieval step. Although this should only impact the absolute metrics and not the relative comparison, we also computed the results filtering out questions with no retrieval information. However, the results of the filtered version did not differ significantly from the original and have been left out of the results.
Procedure
First, the 1.405 documents were uploaded to both Nuclia and Vectara. Then, for each RAG platform, the most simple configuration was used to generate the initial sets of results to the 1.405 questions. It is important to note that both platforms offer a wider range of RAG strategies and retrieval configurations that could potentially enhance the results significantly. However, to ensure a fair comparison, we opted for the more “vanilla” approaches for each platform. This implied deselecting Vectara’s option of adding two sentences before and after each context.
Upon discovering that Vectara’s configuration did not initially include their latest model, we added a second configuration featuring Mockingbird, their latest RAG-focused LLM.
To further enrich the evaluation, another Nuclia variation was included, utilising OpenAI’s English embeddings model.
These four sets of results, along with the context pieces retrieved in each query, were evaluated using REMi and the nuclia-eval library. The metrics used were the RAG Triad metrics provided by REMi : Answer Relevance, Context Relevance and Groundedness. The aggregation for the metrics was done as follows:
- For each of the context pieces in a query:
- Query Context Relevance: The mean of the Context Relevance scores for each context piece. This follows the intuition that ideally all context pieces retrieved should be relevant to the query.
- Query Groundedness: The maximum Groundedness score for all the context pieces, based on the intuition that is it enough for the generated answer to be grounded in at least one of the context pieces.
- For each query the three metrics (Answer Relevance, Query Context Relevance, Query Groundedness) were aggregated using the mean.
Since we are using a dataset with an available ground truth, we extended our analysis beyond the standard REMi metrics by also calculating Answer Correctness to gain deeper insights into the platforms’ performance. This metric measures how accurately the information in the generated answers aligns with the ground truth answers, using a scoring system from 0 to 5, similar to the REMi metrics.
Although Answer Correctness is not part of the core REMi metrics, it can still be calculated using the REMi model by measuring the groundedness between the generated answer and the ground truth answer, rather than comparing it with the context pieces as in the regular Groundedness.
Results
In this section, we analyze the performance of the two platforms—Nuclia and Vectara—across various configurations using the REMi metrics and the additional Answer Correctness metric.
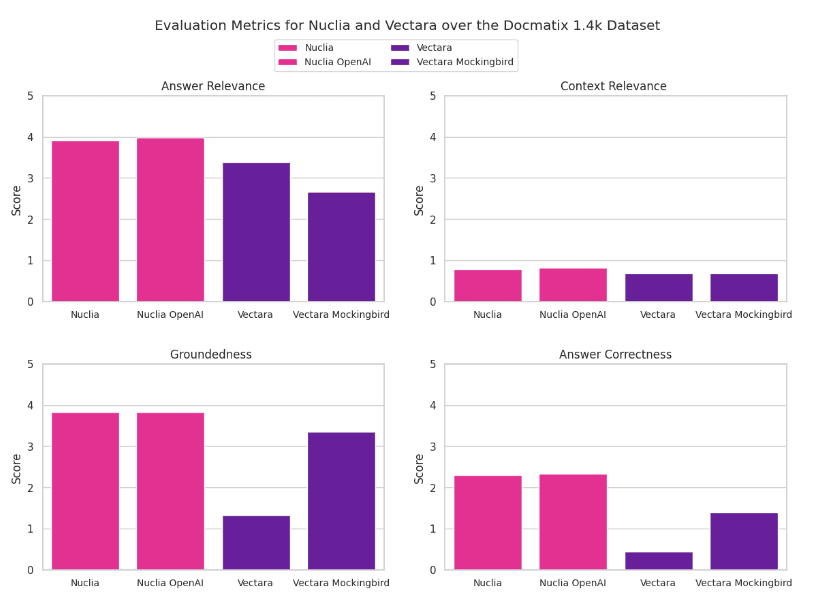
Four bar charts, one for each metric over Docmatix 1.4k for the 4 evaluated configurations.
Nuclia vs. Vectara
The evaluation revealed distinct performance patterns between Nuclia and Vectara. Below is a summary of the key findings across the four configurations tested:
- Nuclia with OpenAI Embeddings: Achieves the highest scores across most evaluation metrics, indicating strong performance in answer relevance, context relevance, groundedness, and answer correctness.
- Nuclia Default Model: Performs slightly worse than Nuclia with OpenAI embeddings but still maintains strong performance across the metrics.
- Vectara Default Model: Exhibits slightly lower performance in retrieval-related results (context relevance), groundedness, and answer metrics compared to Nuclia.
- Vectara Mockingbird: Shows higher groundedness than the default Vectara configuration but performs worse in terms of answer relevance, suggesting a tendency for the default LLM to hallucinate. The higher groundedness and correctness combined with low relevance could also indicate that the Mockingbird LLM may be adding superfluous information not relevant to the initial query, but based on the provided contexts.
|
Nuclia Default |
Nuclia OpenAI embeddings |
Vectara Default |
Vectara Mockingbird |
|
|
Answer Relevance |
3.92 |
3.98 |
3.38 |
2.67 |
|
Context Relevance |
0.79 |
0.82 |
0.69 |
0.69 |
|
Groundedness |
3.84 |
3.83 |
1.33 |
3.36 |
|
Answer Correctness |
2.31 |
2.34 |
0.44 |
1.39 |
Table with the evaluation results over Docmatix 1.4k for the 4 evaluated configurations.
These results indicate that Nuclia, particularly when enhanced with OpenAI embeddings, excels in delivering relevant and grounded answers. This superior performance suggests that the combination of advanced embeddings with Nuclia’s platform leads to more accurate retrieval and generation of answers, making it a strong candidate for applications requiring high precision.
On the other hand, Vectara’s performance highlights areas for potential improvement. The lower scores in Answer Relevance and Answer Correctness, especially in the default configuration, suggest that while Vectara can retrieve relevant data, the link between the data and the generated answers might not be as robust as with Nuclia with the chosen configuration.
Future work
We acknowledge the limited scope of this comparative analysis and leave the door open for further comparisons in the future in three different directions:
- Evaluating More Platforms:
- Expanding the range of platforms evaluated to include a broader spectrum of technologies and methodologies.
- This will provide a more comprehensive understanding of the strengths and weaknesses of various systems.
- Evaluating on Different Datasets:
- Conducting evaluations on a variety of datasets, encompassing diverse topics and different types of files.
- This will add richness to the comparison and provide insights into how different platforms perform under varied conditions and data formats.
- Evaluating Across Different Retrieval-Augmented Generation (RAG) Strategies:
- Exploring and comparing various RAG strategies to determine which approaches yield the best results.
- This will help in identifying the most effective techniques for enhancing answer relevance, context relevance, groundedness, and answer correctness.
By pursuing these directions, future work can provide a more detailed and nuanced understanding of the capabilities and limitations of different platforms and methodologies.



