
Even though REMi v0 was the first of its kind, since then other models of similar size have been released that have RAG evaluation capabilities. One of those models is IBM Granite-Guardian 3.1, which can evaluate multiple risks, three of these risks are the answer relevance, context relevance and groundedness in a RAG context.
In our internal testing, the RAG evaluation provided by the Granite-Guardian models do not perform as good as REMI, with scores that depart from human judgment more often than our latest REMI. Let’s exemplify the difference between REMi-v0, Llama-REMi-v1 and Granite-Guardian in its biggest size through two example RAG interactions.
The code used to run the evaluation for the Granite-Guardian 3.1 8B model is taken from the official IBM examples here. Since their scores measure close to one if the risk is present (i.e. if not relevant or not grounded) we have inverted them (close to zero if not relevant or not grounded) for the purpose of easier comparison.
These interactions have been created just for this article and are not contained on any of our training datasets. We present human evaluation scores as ranges to accommodate the inherent variability in human assessments and ensure flexibility in interpretation.
Example RAG Interaction 1
| Question | “What equipment is essential for indoor bouldering?” |
| Answer | “The essential equipment for bouldering includes climbing shoes, a chalk bag, and, if bouldering outdoors, a bouldering pad. Additional useful items include a piece of carpet or matting to keep shoes clean, a tarp to protect the pad in wet conditions, and a guidebook for navigation.” |
| Contexts |
|
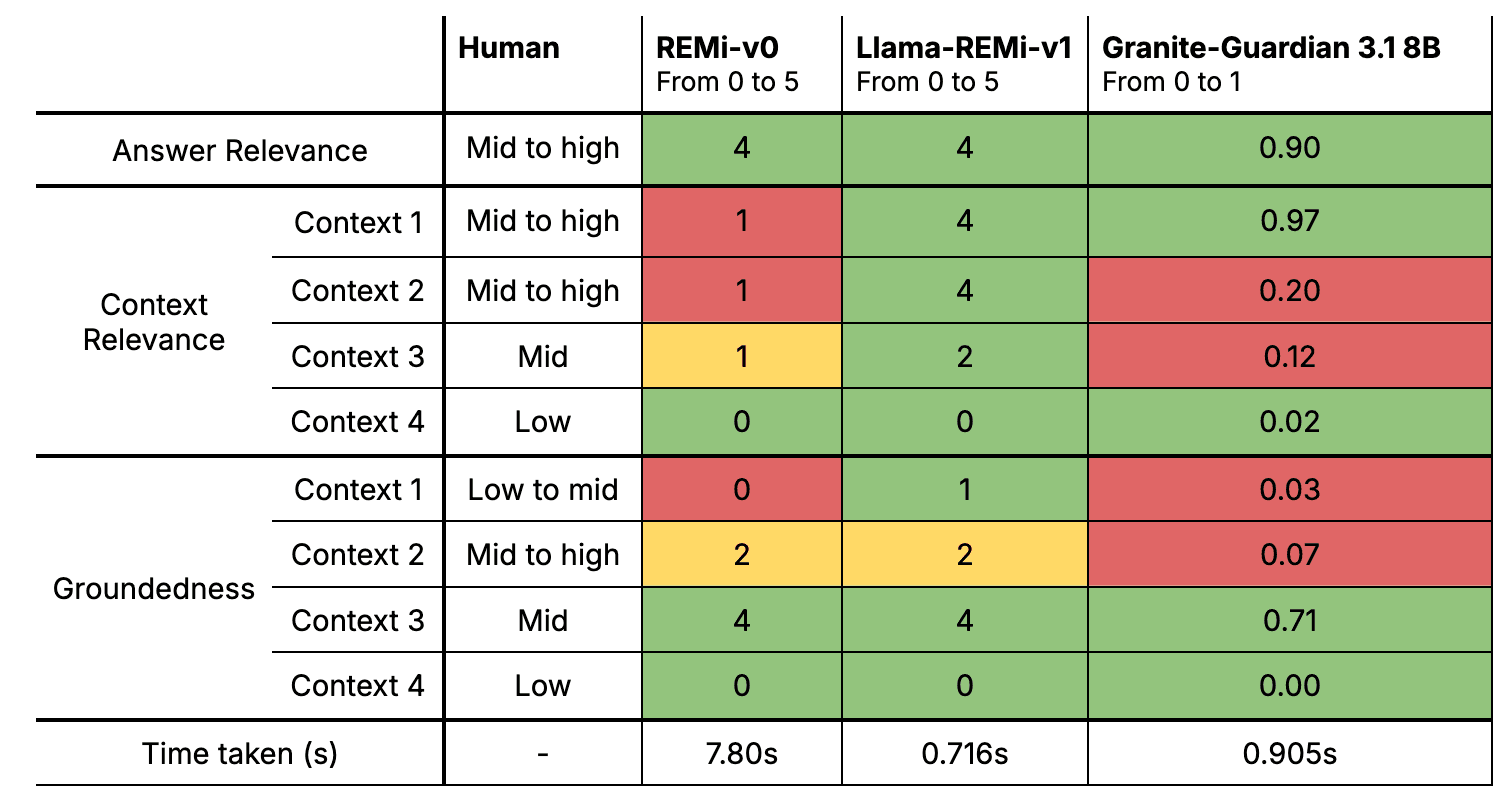
In this second evaluation, Llama-REMi-v1 once again proves to be the model most closely aligned with human judgment, particularly in multilingual contexts. It demonstrates a clear advantage across the board, outperforming both REMi-v0 and Granite-Guardian 3.1 8B. The latter exhibits notable weaknesses, especially in evaluating multilingual contexts and in failing to assign a high relevance score to a perfect answer presented in list form.
Example RAG Interaction 2
| Question | “What are the specs of the OP-1 display?” |
| Answer |
“The specs of the OP-1 display are: – AMOLED display running at 60 fps – 320 x 160 pixel resolution – Color Depth: 16.7 M – Contrast: 10000:1 (good for outdoor use) – Viewing Angle: 170° – Life Time: 30,000 h” |
| Contexts |
|

In this second evaluation, Llama-REMi-v1 once again proves to be the model most closely aligned with human judgment, particularly in multilingual contexts. It demonstrates a clear advantage across the board, outperforming both REMi-v0 and Granite-Guardian 3.1 8B. The latter exhibits notable weaknesses, especially in evaluating multilingual contexts and in failing to assign a high relevance score to a perfect answer presented in list form.
Comparison
When comparing the RAG evaluation of Llama-REMi-v1 with Granite-Guardian 3.1, key differences emerge in the data strategies and the interpretability of results, showcasing the unique strengths of Llama-REMi-v1:
Production-Aligned Data vs. Standard Data:
– Granite-Guardian’s RAG training dataset relies exclusively on synthetic data generated from curated datasets such as HotPotQA, SQuADv2, MNLI, and SNLI. While these datasets are ideal for controlled experimentation, they generally do not accurately reflect the messy, diverse and unstructured nature of real-world data.
– Llama-REMi-v1’s training dataset, although it includes synthetic data, contains context pieces that have been extracted and chunked directly from real documents, including markdown-structured text. This ensures the model has seen data that mirrors the complexity of production environments.
Multilingual Capability:
– With its English-only training data, IBM Granite-Guardian 3.1 is limited in its ability to serve multilingual or international use cases effectively.
– Llama-REMi-v1’s multilingual training data equips it for a wider range of applications, catering to global audiences and supporting diverse linguistic environments.
Interpretability of Metrics:
– IBM Granite-Guardian 3.1 consolidates its evaluation into a binary result with the option obtain a score for each metric, which is done through the token decoding probabilities of the risk or safe token, which may lack granularity.
– Llama-REMi-v1 takes a client-centric approach by not only giving discrete scores for each of the metrics, but also providing a detailed reasoning for the answer relevance score. This makes results more interpretable and actionable, empowering clients to better understand the areas for improvement in their RAG pipelines.
By embracing real-world-aligned data, multilingual support, and a more interpretable evaluation, Llama-REMi-v1 by Nuclia stands out as a practical and client-focused solution. These strengths make it more adaptable and robust compared to the controlled but limited approach of IBM’s Granite-Guardian 3.1.



